Two days ago, I updated Pritunl to the latest stable version, specifically v1.32.4057.36. Today, as users started connecting more frequently, the following errors began appearing more often, which disconnected all users from the server and prevented them from reconnecting via either OpenVPN or WireGuard:
[ERROR] Client lost unexpectedly
and [ERROR] Client pool lost unexpectedly
At the same time, the web UI took a long time to load data about servers, users, and logs, which led me to suspect potential issues with the database (Mongo Atlas 6.0.18).
I set up a local database, but this did not solve the problem. Only rolling back to the previous stable version, 1.32.3805.95, helped.
Those errors often occur when the database queries cannot be completed fast enough. The new release has pyMongo v4 which increased the default write concern. The software can handle a lot of inconsistent data so it was never increased beyond the default unacknowledged writes. The new library defaults to acknowledged and MongoDB is moving towards using this as a best practice.
This is more of a problem with your database, it should be able to handle the slightly increased write concern. If it is a shared M2/M5 cluster those are not for production use and shouldn’t be used.
Yesterday evening, the same issue occurred, ruling out the latest stable version and showing that the initial interpretation of the problem was incorrect. Here’s what happened:
For a brief period, Pritunl VPN lost internet connection due to issues with the internet provider, causing all clients to disconnect. When the internet connection was restored, clients started experiencing connection issues with the VPN. OpenVPN connected, but WireGuard didn’t work at all. The Server Output showed an endless list of logs like:
User disconnected user_id=63ecd6957e8************
User connected wg user_id=63ef59457e8************
User disconnected user_id=63ef59457e8************
User connected wg user_id=669f5f096dd************
User disconnected user_id=669f5f096dd************
...
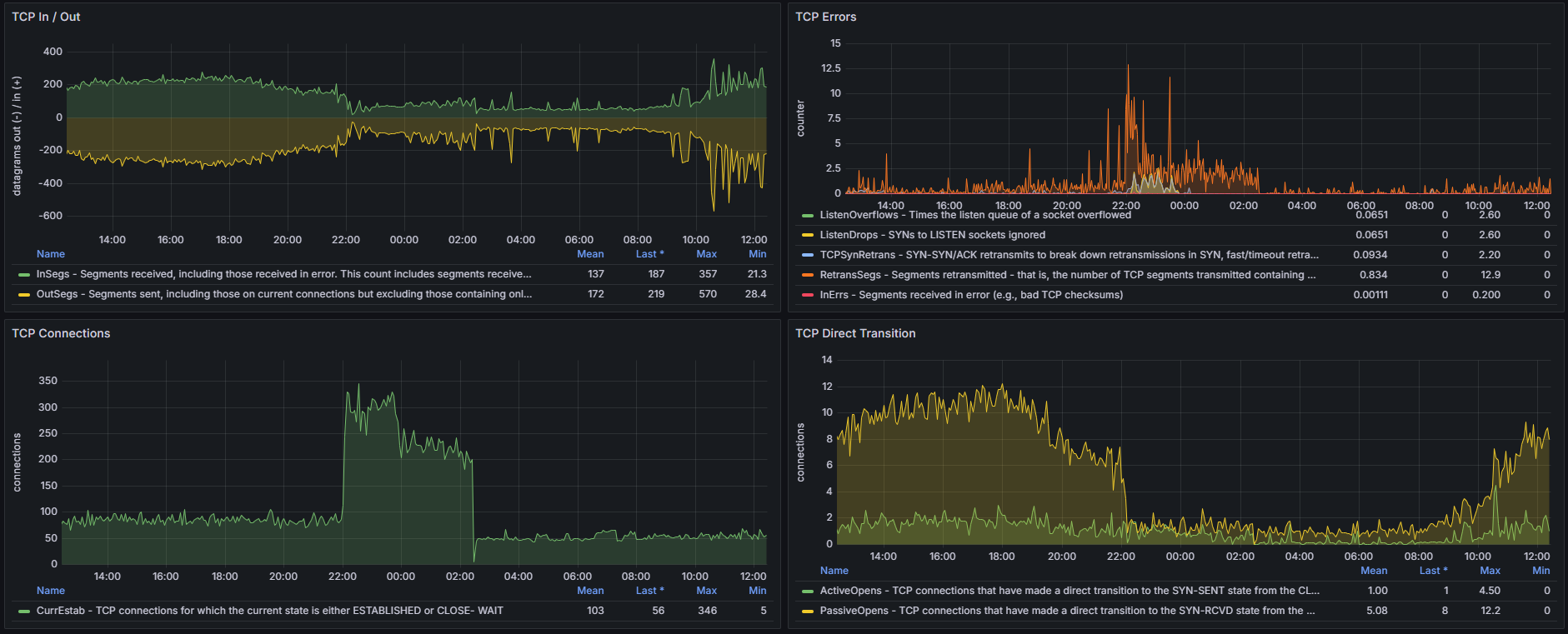
During this time, the web UI was barely responsive. The server list and logs could take over a minute to load. I noticed a significant increase in TCP connections as clients tried to reconnect, visible in the monitoring screenshot.
I was only able to resolve the issue by stopping all servers and restarting Pritunl VPN. Could this be due to incorrect client operation, or is there another cause?
Those two documents contain a timestamp and the collections have expire indexes that remove the documents after about 5 minutes. The server updates the timestamp every 2.5 minutes, if the update doesn’t occur within that time the document is removed and that error occurs.
This most commonly occurs when the server is overloaded and the update thread is delayed allowing the documents to expire or the database is overloaded and cannot process the updates before it expires. Both the database and Pritunl hosts should be monitored to see if there is enough CPU and memory.
It also possible the server lost connectivity to the database for some time allowing the documents to expire. If this occurs the errors may only show up in /var/log/pritunl.log if the server isn’t able to reach the database to store the logs.
Are there any options for using a local replica of Mongo Atlas to avoid issues in case of an unstable internet connection? Sorry, I’m not very experienced with MongoDB.
Regarding CPU and RAM resources, they are currently more than sufficient for this host, so there are definitely no performance issues.
If there is only one host there is no need to use MongoDB Atlas. If there are multiple hosts only one MongoDB server can be the primary and MongoDB Atlas doesn’t support external replicas.
Of course, we started using MongoDB Atlas because we plan to connect more hosts in different locations.
Shouldn’t there be a function for Pritunl to automatically recover its state after a desynchronization with MongoDB? This can happen at any time, and we’re facing significant issues where users get disconnected and can’t reconnect until we restart the Pritunl service.If we don’t stop the servers in the UI before restarting the Pritunl service, we encounter the following error in the logs after the restart:
[WARNING] Stopping duplicate instance, check date time sync
This leads to continued lag. Is this considered a bug, and if so, are there plans to fix it?
That log message is just from clearing the document of the previous instance that was stopped.
The server will recover, the server instance document has a longer timeout. If the server cannot reach the database before that timeout it will stop the instance and a recovery will start it again.
The server not automatically restarting is likely an issue with the messaging system or just the server unable to keep the tailable cursor active to receive the startup message. The server startup timeout error will often occur when there is an issue with this. Stopping the hosts and clearing the cache collections with sudo pritunl destroy-secondary may fix it. I’ve seen a lot of issues with capped collections and tailable cursors on MongoDB Atlas.
We experience the same issues. I was just wondering if optimizing your MongoDB actually solved the issue on your end? In our case, the fastest approach to resolve the issue was actually to restore a backup and on the test system, we do not get enough usage to actually hit the issue, so debugging is a bit complicated.
Hi @janaurka
At the moment, we haven’t encountered this issue again. However, we are considering automating a mechanism to detect similar issues, clear cache collections, and restart the service.
The commands below can be used to clear the temporary data in the database. The hosts should be stopped before running these commands. The repair database command will clear the most data and will also reset all user assigned IP addresses.